 Skip to content
Skip to content
.png?width=1920&height=1080&name=Landscape%20(4).png)


Karpenter offers advanced scheduling and auto-scaling capabilities for EKS, improving application availability and cluster efficiency by rapidly launching right-sized compute resources in response to changing application load.
One key benefit of Karpenter is its built-in native support for Spot instances. EC2 Spot Instances are spare EC2 capacity available for up to 90% off compared to On-Demand prices. However, Spot instances can be interrupted by AWS when the capacity is needed back. Karpenter makes it easier to save with Spot by automatically cordoning and draining nodes, and launching a new node as soon as it sees the Spot interruption warning.
In this article, we’ll walk you through why Spot-to-Spot consolidation is critical, how it works and how to use it.
Since v0.34.0, you can enable the feature gate to use Spot-to-Spot consolidation. This feature can be enabled during a helm install of the Karpenter chart by adding –-set settings.featureGates.SpotToSpotConsolidation=true argument, or it can be configured post initial installation by using Karpenter environment variables or CLI parameters, more info here.
Why do I need Spot-to-Spot Consolidation? A real-world Kubernetes billing horror story
Without Spot-to-Spot consolidation, nodes running Spot instances may continue to operate underutilized or idle after their initial workloads have completed.
Consider this very common scenario: You’re scheduling big batches of workloads, which tend to get scheduled on very large worker nodes.
Without Spot-to-Spot consolidation, Karpenter won’t consider consolidating the workloads that are on your Spot instances. That means that if you’ve finished half of those workloads, the pods go away — but half of those nodes are left sitting there still running, driving up costs indefinitely.
In the real world, we see this all the time. Often, teams don’t even know how much excess capacity they have in their Kubernetes clusters.
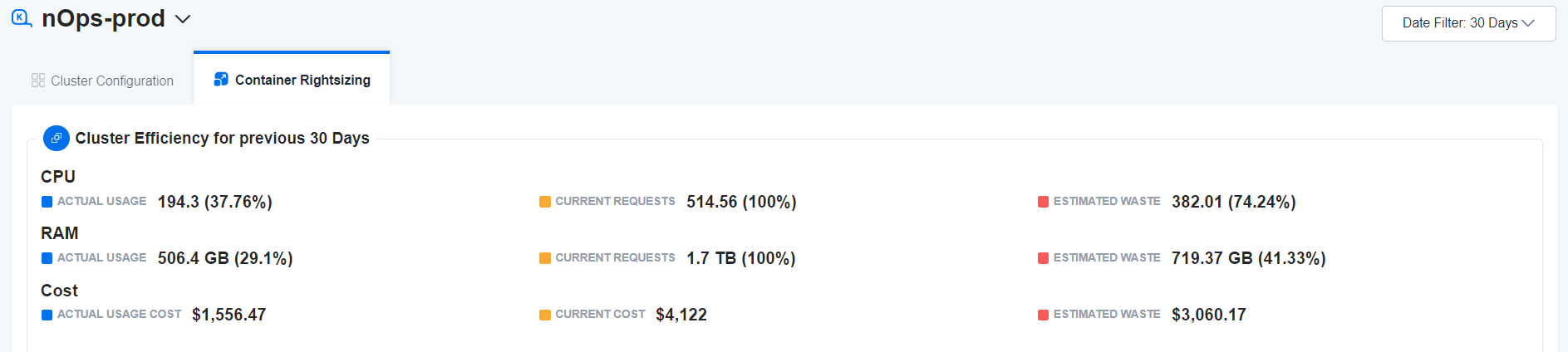
If this sounds familiar, the nOps dashboard shows you at a glance how much excess capacity you have in your clusters.
If you’re excess capacity is very high, you can look at your container usage over time to ask why this is the case. If you’re nodes aren’t being consolidated very well, the Spot-to-Spot consolidation feature just might be the solution to your problem.
How Spot-to-Spot Consolidation works
Let’s explore this Karpenter feature and how it works, before getting into some best practices.
Karpenter Workload consolidation
First, let’s briefly take a step back and talk about workload consolidation in Karpenter.
Karpenter works to actively reduce overprovisioning and thus cluster cost by identifying opportunities to consolidate nodes. This occurs when:
- Nodes can be removed because the node is empty
- Nodes can be removed as their workloads can be rescheduled onto other nodes in the cluster.
- Nodes can be replaced with lower priced and rightsized variants due to a change in the workloads.
In general, Karpenter prefers to terminate nodes running fewer pods, nodes that will expire soon, and nodes with lower priority pods.
Spot Consolidation in Karpenter
Karpenter simplifies the management of Spot instances with its Default Deletion Consolidation setting, which automatically removes Spot nodes when they are no longer needed or can be replaced for cost efficiency.
For more aggressive savings, users can enable the SpotToSpotConsolidation feature flag, allowing Karpenter to replace existing Spot nodes with other Spot nodes to further enhance cost savings.
Instance Type Flexibility
Karpenter uses a price-capacity-optimized strategy to select lower-priced Spot instances. This strategy does not always opt for the absolute lowest priced instance due to the risk of interruption, which can result in higher costs due to frequent replacement and downtime. Instead, it considers a range of options that still offer cost savings but with lower interruption risks.
Karpenter assesses “instance type flexibility,” or the number of available Spot instance types priced lower than the currently launched Spot instance. This flexibility is crucial for:
- Avoiding High Interruption Rates: By not always selecting the lowest priced instance, Karpenter avoids nodes that are highly likely to be interrupted, ensuring greater stability and reduced downtime.
- Ensuring Comparable Availability: Karpenter launches instances with enough types to ensure that the replacement instance has a similar availability profile to the current one.
The Ultimate Guide to Karpenter

For single-node Spot-to-Spot consolidations, Karpenter requires a minimum of 15 instance types to ensure sufficient flexibility. This prevents a “race to the bottom” scenario where nodes are continuously replaced with the cheapest, but least stable, instances. Multi-node consolidations do not have this flexibility requirement since the likelihood of “race to the bottom” is minimized when consolidating multiple nodes into one.
The following is an example of a flexible and diversified NodePool:
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c", "m", "r"]
- key: karpenter.k8s.aws/instance-size
operator: In
values: ["medium" , "large", "xlarge", "2xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["Spot"]
nodeClassRef:
name: default
To sum it up, Karpenter’s Spot consolidation, especially when enhanced with the Spot-to-Spot replacement feature, can help dramatically improve your cost and operational efficiency.
Container visibility & rightsizing made easy
The first step to reducing your Kubernetes costs is visibility. With nOps Business Contexts+, it’s fast and easy to understand and allocate 100% of your unified EKS and AWS costs — from your largest resources all the way down to your individual container costs.
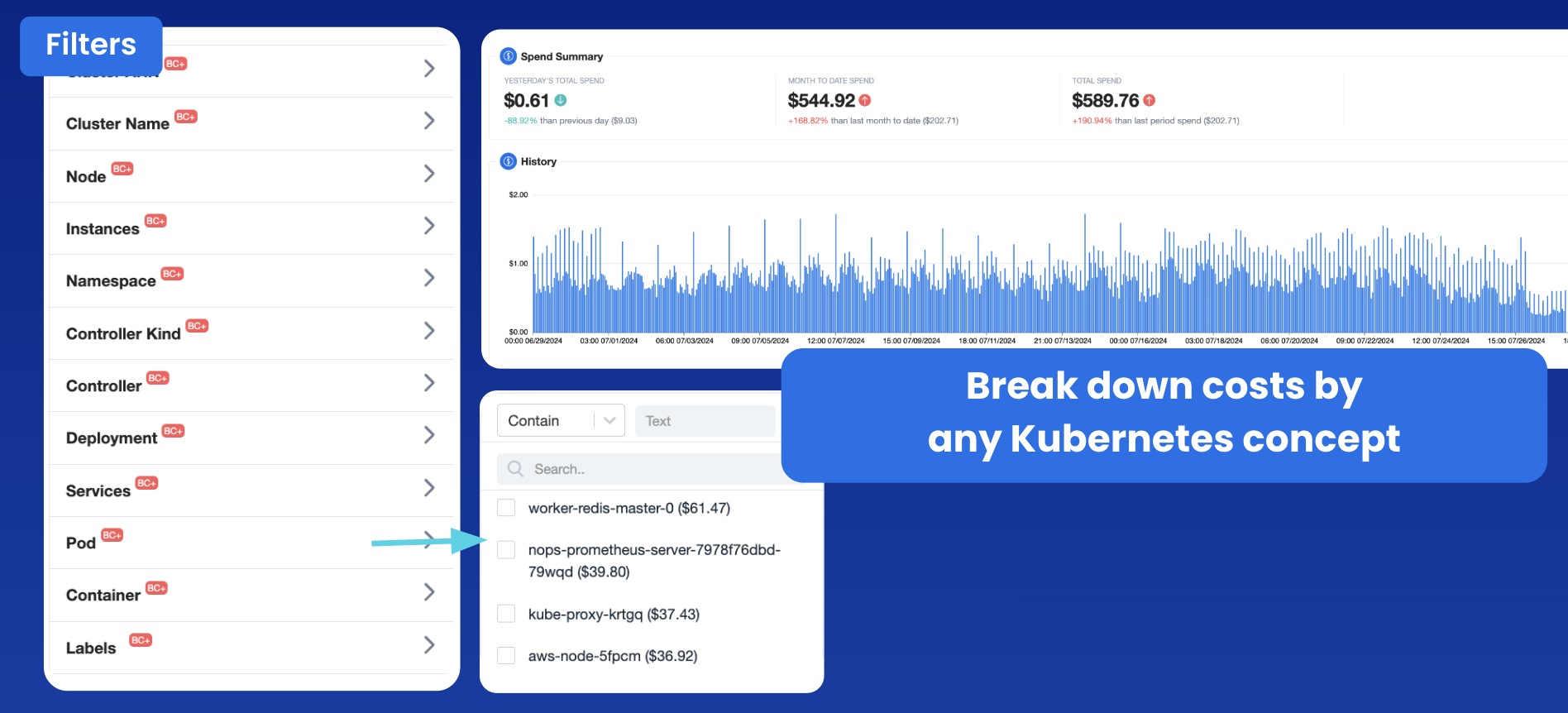
You can filter based on any Kubernetes concept down to the node or pod level, for complete visibility into the allocation of resources within your Kubernetes clusters.
The Cluster Efficiency provides detailed insights and actionable recommendations on how to adjust your container deployments for optimal performance and cost.
nOps continually processes massive amounts of near real-time and historical data from multiple sources including your AWS Cost and Usage Report (CUR) for the most accurate, high-resolution view of your costs down to the penny.
You can review the granular historical data backing each recommendation right in the dashboard — so you can act with the utmost confidence in the reliability of recommendations.
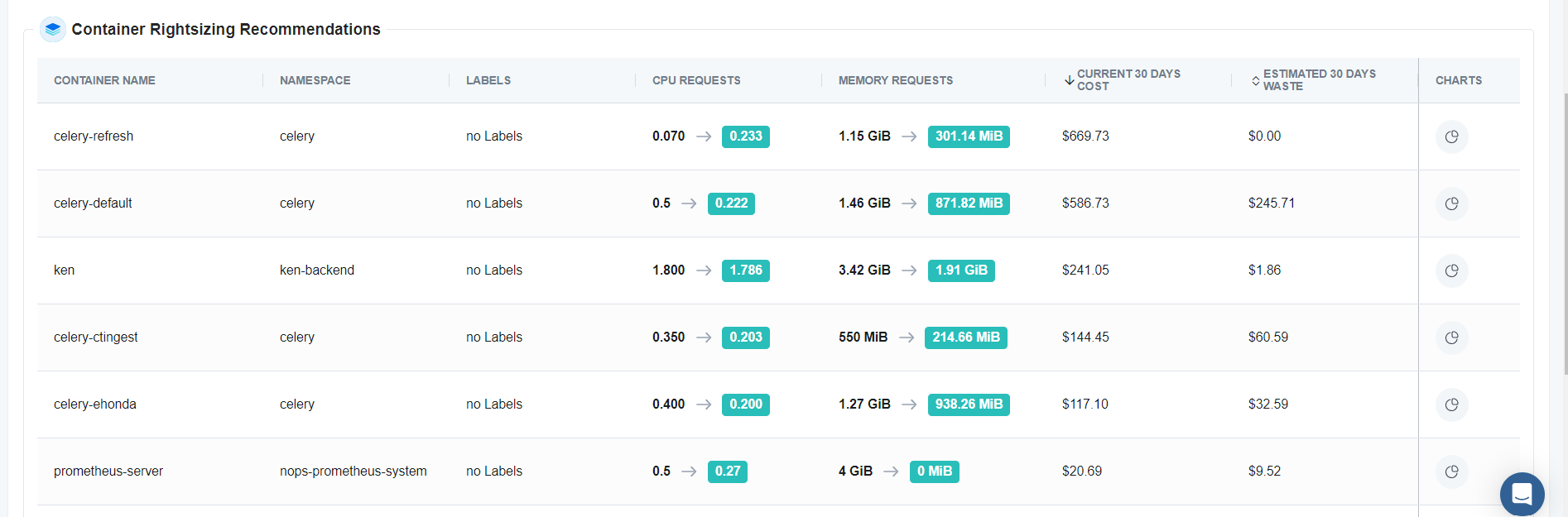
Coming soon, you can one-click apply Container Rightsizing Recommendations in the nOps dashboard to save even more engineering time and effort. Our mission is to make Kubernetes optimization easy, so that you’re freed up to focus on building and innovating.
nOps was recently ranked #1 in G2’s cloud cost management category, and we manage $1.5 billion in AWS spend for our customers. Book a demo to find out how to save in just 10 minutes.








