Skip to content
Skip to content


- Blog
- EKS Optimization
- Managing Commitments with Karpenter: The Hard Way vs. How nOps Makes It Effortless
Managing Commitments with Karpenter: The Hard Way vs. How nOps Makes It Effortless
Karpenter is steadily gaining popularity because of its ability to dynamically provision compute resources in real-time, optimizing instance types and sizes based on actual workload requirements for better performance, lower costs, and reduced waste.
However, managing commitments with Karpenter can be a challenge. Karpenter is not inherently aware of your Reserved Instances or Savings Plans, which are typically prepaid to reduce costs for sustained usage. Karpenter focuses on real-time scaling using Spot Instances, which can conflict with these prepaid commitments. Since Karpenter doesn’t recognize or prioritize using Reserved Instances or Savings Plans, there’s a risk of accidentally over-relying on Spot Instances, leading to “double-paying”—using Spot while still being charged for unused commitments.
In this article, we’ll walk you through some common Karpenter challenges relating to commitment and Spot management — and what you can do to address them.
Challenges with Karpenter
1. Commitment Underutilization
Challenge: Karpenter is unaware of your Reserved Instances or Savings Plan commitments and cannot automatically optimize for them. As a result, while Karpenter scales to meet workload demand, it might overprovision Spot Instances, leading to underutilized pre-purchased capacity from RIs or Savings Plans—ultimately resulting in missed savings opportunities and wasted costs.
Workaround: You can manually configure Karpenter’s NodePools to prioritize On-Demand instances that align with your commitments. For example, if you have Reserved Instances (RIs) for m5.large and m5.xlarge instances, you can restrict the NodePool to provision these instance types.
apiVersion: karpenter.sh/v1alpha5 kind: Provisioner metadata: name: commitment-provisioner spec: requirements: - key: "node.kubernetes.io/instance_type" operator: In values: ["m5.large", "m5.xlarge"] # Match RIs/Savings Plans instance types capacityType: "on-demand" 2. No Holistic Spot Orchestration
Challenge: Karpenter provisions nodes based on current resource availability but lacks a comprehensive Spot instance strategy. It does not automatically diversify across instance types or manage Spot lifespans, which increases the risk of interruptions and operational complexity.
Workaround: You can manually define multiple instance types within Karpenter’s NodePools to encourage diversified Spot instance selection.
apiVersion: karpenter.sh/v1alpha5 kind: Provisioner metadata: name: spot-provisioner spec: requirements: — key: "node.kubernetes.io/instance-type" operator: In values: ["m5.large", "c5.large", "r5.large"] # Diversify instance types capacityType: "spot" 3. Lack of Visibility
Challenge: Karpenter lacks built-in tools to monitor metrics like termination rates, node performance, and cost efficiency, which can make it difficult to evaluate whether autoscaling effectively aligns with budget goals or makes optimal use of RIs and Savings Plans.
Workaround: To fill this gap, integrate third-party monitoring tools such as Prometheus, CloudWatch, or custom dashboards to gather insights into Karpenter’s performance.
It’s worth noting that setting up and maintaining these integrations requires considerable effort, including custom alerts, dashboards, and tuning for critical metrics. This approach allows you to assess performance and costs but adds a layer of complexity.
The Time and Effort Behind Manual RI and Spot Optimization
Manually managing Reserved Instances (RIs), Spot instances, and other cloud commitments with Karpenter requires considerable engineering effort:
- Initial Setup: Configuring Karpenter to prioritize RI utilization and set up third-party monitoring typically takes 25-32 hours, including defining compatible instance types and building monitoring dashboards.
- Ongoing Maintenance: Each month, engineers usually spend 15-25 hours monitoring RI usage, adjusting configurations, and managing Spot instance stability. Each time workloads change or AWS releases new instance types or regions, engineers must manually update Karpenter configurations. This continuous fine-tuning becomes especially time-consuming as infrastructure scales.
How nOps Simplifies This Process
nOps automates commitment and Spot management, potentially saving up to 80% of engineering time while continuously optimizing instance usage. This automation not only improves cost efficiency by 5-15% but also allows engineering teams to focus on higher-impact work.
In the next section, we’ll dive into how nOps achieves this.
nOps Karpenter: Making Commitment Management Effortless
At nOps, we’ve enhanced Karpenter by providing a comprehensive approach to managing cloud commitments like RIs, Savings Plans, and Spot Instances. Our solution helps you avoid the manual headaches of balancing cloud commitments with real-time autoscaling.
Here’s how nOps Karpenter turns the manual way into an effortless experience:
1. Maximize Cost Efficiency with Automated Commitment Alignment
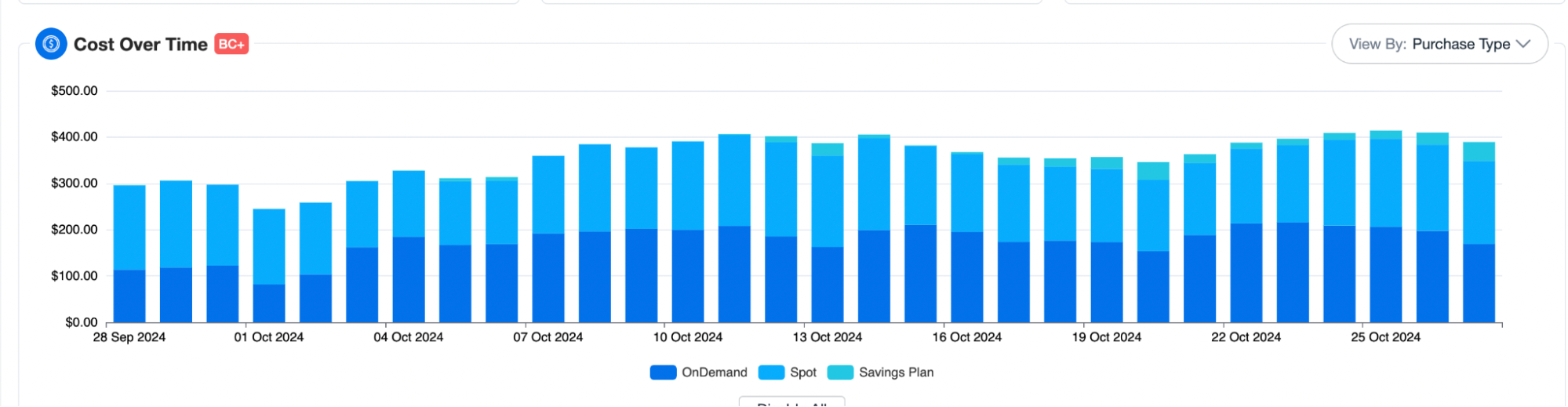
Instead of manually juggling Spot, RIs, and Savings Plans, nOps automatically aligns your Karpenter cluster provisioning with your existing commitments. This means no more underutilized RIs and no wasted Savings Plans — every dollar you’ve committed will be working for you. Here is an example of nOps’ production EKS cluster: nOps is juggling across Spot, saving plans, and on-demand. We pick the most optimal compute to deliver maximum savings and reliability.
2. Better Outcomes with Spot
nOps improves Spot instance management over traditional methods by using machine learning to monitor real-time Spot market pricing and interruption trends. The result is better performance at lower costs.
nOps dynamically shifts workloads to the most reliable and cost-effective Spot instances available, diversifying instance types and regions to minimize the risk of sudden interruptions. Unlike typical Spot management, which often replaces instances reactively, nOps proactively rebalances workloads based on predictive insights for more savings and stability. Additionally, nOps provides a centralized dashboard with real-time visibility into Spot performance and cost metrics, simplifying optimization and decision-making.
3. Intelligent Instance Selection & Continual Workload Reconsideration
With nOps, engineers no longer need to manually select and configure instance types for their workloads. nOps automatically identifies and deploys the most optimal Spot and On-Demand instances based on real-time workload demands and historical usage patterns. This intelligent instance selection diversifies across instance types and families, ensuring the right balance of cost and performance while accounting for workload-specific needs. By leveraging Spot Instances when appropriate, nOps helps further reduce costs, while On-Demand instances provide stability for critical workloads, all without requiring hands-on configuration from your team.
nOps not only streamlines instance selection but also continuously monitors for any changes in workload requirements. This automated adaptability means that as your workload scales or evolves, nOps will automatically reassess and adjust the instance types and sizes, ensuring your resources remain right-sized for optimal performance and efficiency. With these intelligent selections, organizations reduce time spent on manual configurations and avoid underutilization or overprovisioning, effectively operating at peak efficiency across AWS environments.

4. All-in-One EKS Visibility
Gaining visibility into workloads often requires multiple tools like Datadog, Cost Explorer, and Lens, complicating access to real-time insights on costs, performance, and workloads. For example, Lens provides detailed Kubernetes insights, but it is resource-intensive and requires elevated access and multiple steps to use.
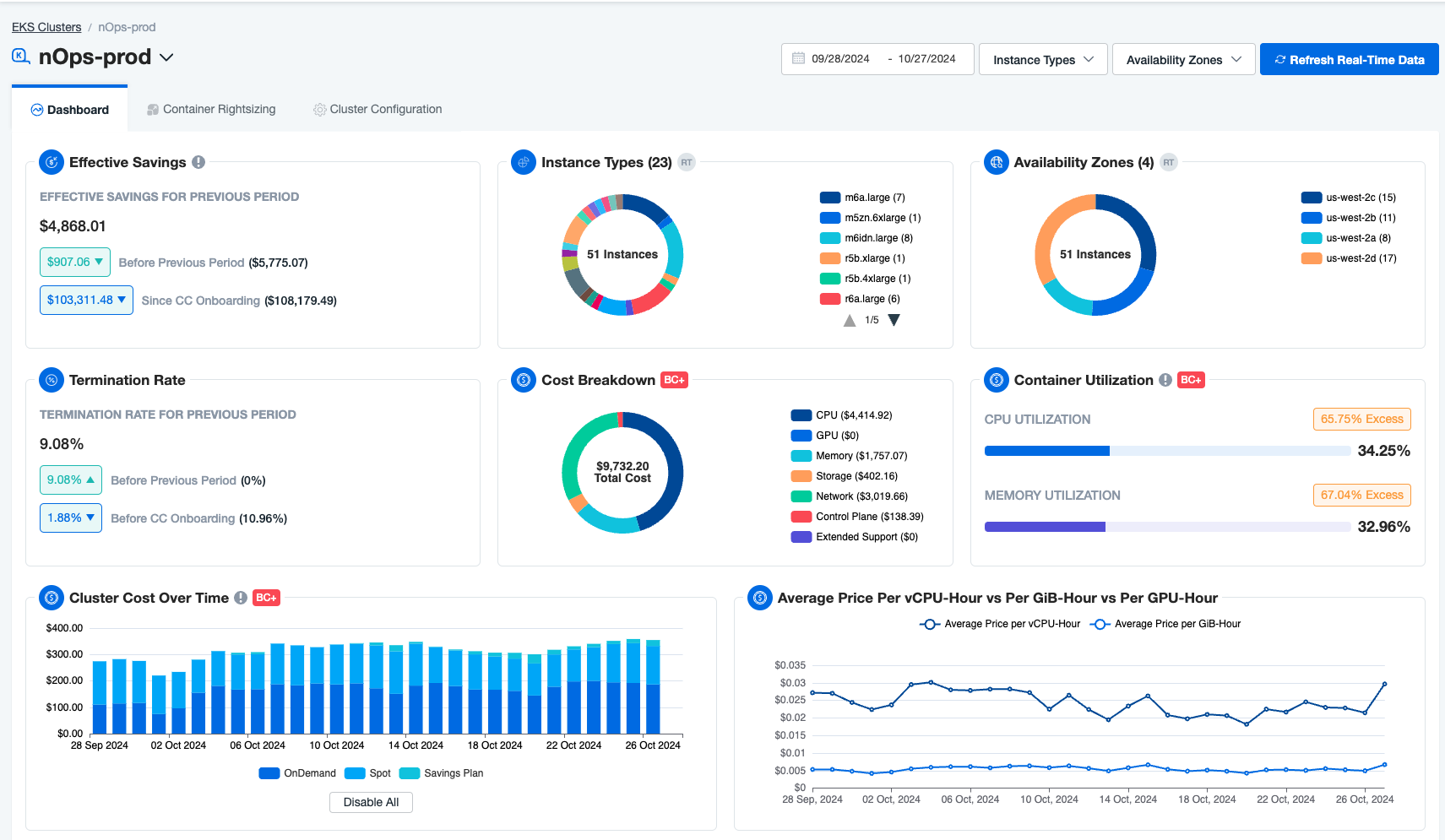
With nOps, this complexity is streamlined. The nOps Kubernetes Dashboard offers Lens-level visibility — including node monitoring, container rightsizing, workload troubleshooting, and binpacking — all in one tool. Tailored for developers and DevOps engineers, the nOps dashboard provides a unified UI for monitoring and troubleshooting workloads at scale with clear, critical metrics and insights.
5. Container Rightsizing
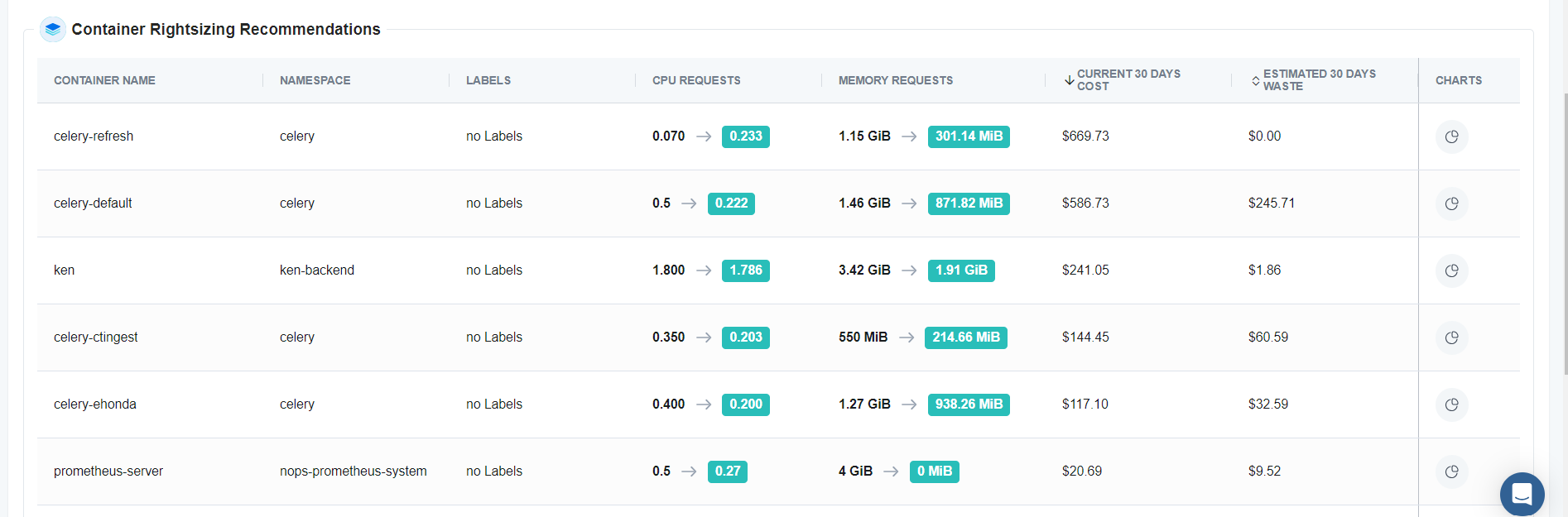
nOps also supports container rightsizing by continuously monitoring detailed historical data to provide precise recommendations for optimizing container efficiency. You can review the data backing each recommendation in the nOps dashboard, allowing confident action to ensure resource-efficient workloads.
The upcoming One-Click Auto-Rightsize feature allows you to apply these recommendations instantly, choosing from options like maximal savings, maximal availability, or a balanced approach.
Karpenter + nOps Are Better Together
nOps Compute Copilot, built on Karpenter, is designed to make it simple for users to maintain stability and optimize resources efficiently.
To maximize EKS cost and performance, automation is key. nOps helps engineering teams more easily and effectively leverage the power of Karpenter, Spot, and AWS commitments for cost savings and reliability, freeing them to focus on building and innovating.
New to Karpenter? No problem! The Karpenter experts at nOps will help you navigate Karpenter migration. We also support multiple autoscaling technologies, like Cluster Autoscaler and ASGs.
nOps was recently ranked #1 in G2’s cloud cost management category. Book a demo to find out how to save in just 10 minutes!
Last Updated: April 28, 2026, EKS Optimization
Last Updated: April 28, 2026, EKS Optimization