 Skip to content
Skip to content
.png?width=1920&height=1080&name=Landscape%20(4).png)


With dozens of announcements and blogs published each week, it can be challenging to sift through and understand the most impactful updates in the world of AWS.
That’s why we developed this monthly series highlighting the most notable recent AWS news and thought leadership in FinOps and GenAI, curated by the nOps engineering team.
Find out what’s new, what’s hot, and what’s going to save you money on your AWS bill.
This month includes the general availability of cheaper Graviton4 instances, preventing problematic GenAI behaviors like hallucination, how to not die during IPv6 migration, new MAP incentive credits, new Llama models, and more.
July 2024: The latest in AWS FinOps
It’s now easier and faster to get Migration Acceleration Program (MAP) credits
AWS Graviton4-powered EC2 R8g instances now generally available
AWS Graviton4-based EC2 instances deliver the best performance and cost efficiency for a broad range of workloads running on EC2. These instances deliver up to 30% better performance compared to Graviton3-based instances.
These long-awaited instances were originally announced 7 months ago at re:Invent — read the official release here.

AWS Glue Studio now offers a no-code data preparation authoring experience
AWS Glue Studio Visual ETL has released “data preparation authoring”, a new no-code data preparation tool with a spreadsheet-style UI for business users and data analysts. This enables scalable data integration jobs on AWS Glue for Spark, simplifying data cleaning and transformation for analytics and ML.
This allows you to scale up data preparation jobs to process petabytes of data at a lower price point for AWS Glue jobs.
GenAI news & updates in July
Llama 3.1 405B, 70B, and 8B models from Meta now in Amazon Bedrock
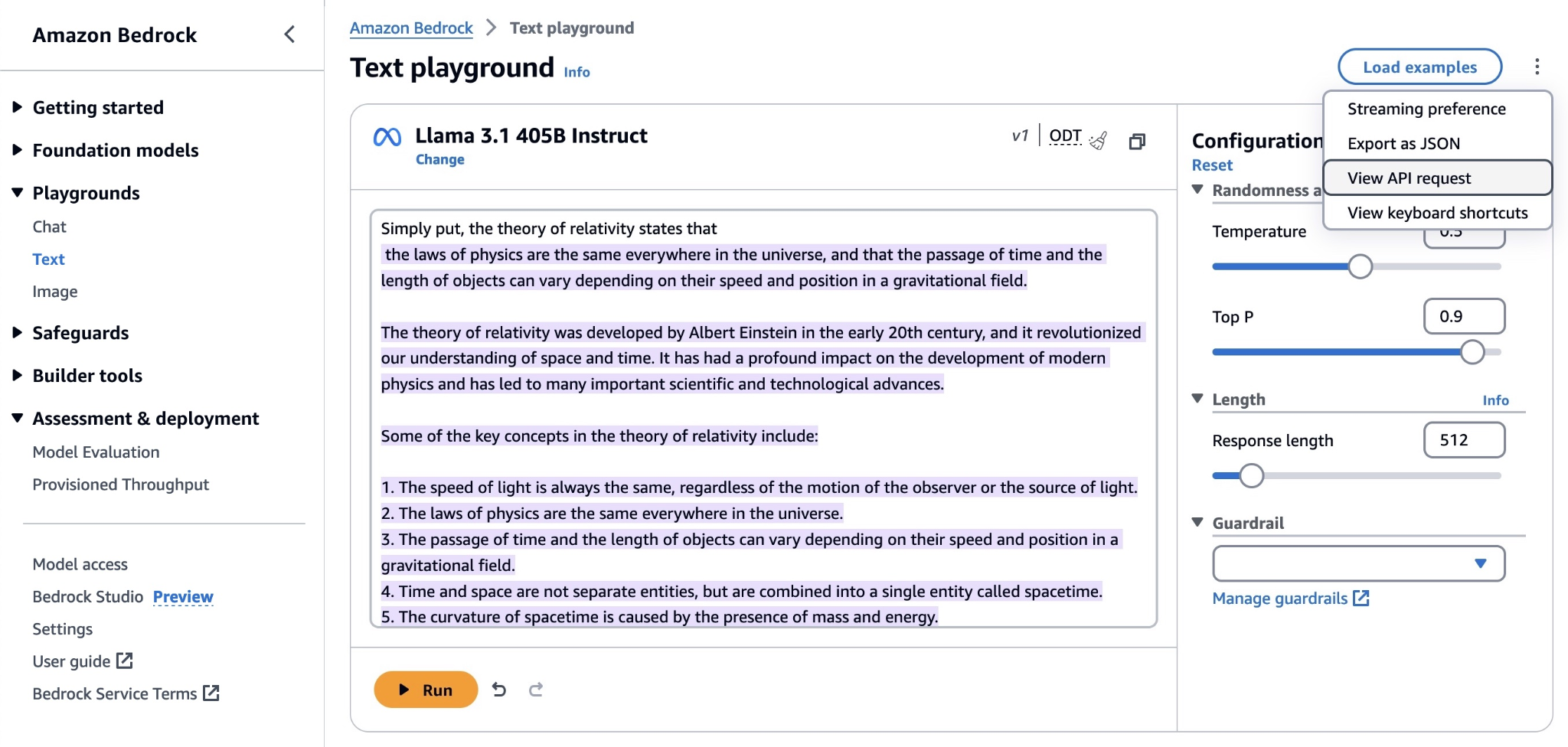
Higher throughput and lower costs on SageMaker
This new inference capability for SageMaker delivers up to ~2x higher throughput while reducing costs by up to ~50% for generative AI models such as Llama 3, Mistral, and Mixtral models.
For example, with a Llama 3-70B model, you can achieve up to ~2400 tokens/sec on a ml.p5.48xlarge instance v/s ~1200 tokens/sec previously without any optimization. This can help you apply optimization techniques like speculative decoding, quantization, and compilation to your generative AI models.
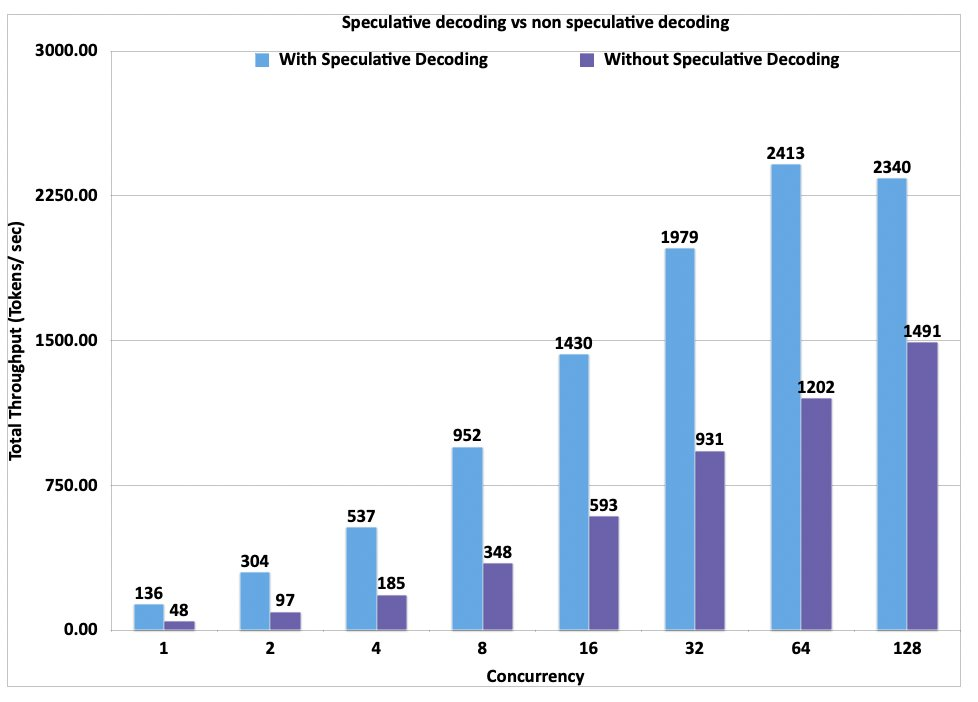
How to choose a database for your GenAI applications
This great post explores the key factors to consider when selecting a database for your generative AI applications.
This includes high level considerations like familiarity, ease of implementation, scalability, performance as well as unique service characteristics of the fully managed databases with vector search capabilities currently available on AWS.
Making Amazon Bedrock models better and less problematic
Multi-modal generative AI capabilities of Amazon Bedrock provide an alternate, easy on-ramp into the world of image analysis, object recognition and more.
However, issues like hallucinations, bias, lack of safety controls can threaten the efficacy of models — check out these recent relevant articles.
- Reduce hallucinations using feedback
- New guardrails for Amazon Bedrock: implement safeguards in your AI applications customized to your use cases and responsible AI policies
- Fine tuning vs RAG: which approach is right for you?
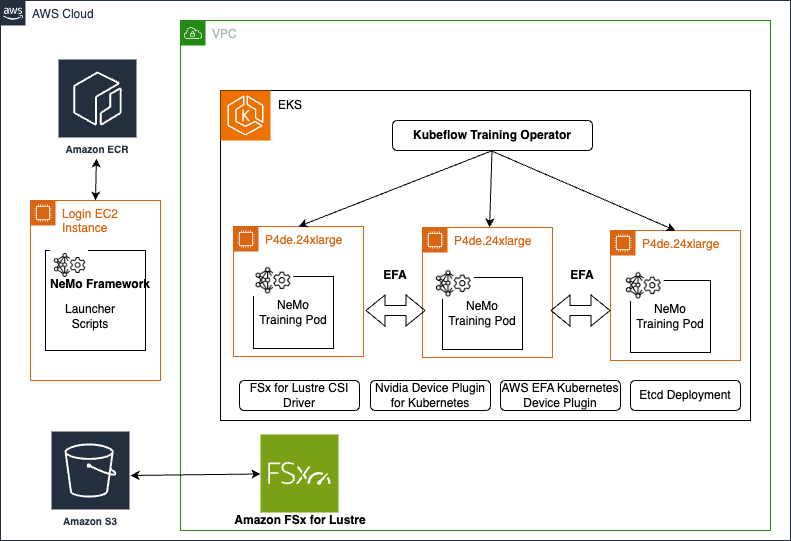
Accelerate your GenAI distributed training workloads with the NVIDIA NeMo Framework
NVIDIA NeMo is an end-to-end cloud-centered framework for training and deploying generative AI models with billions and trillions of parameters at scale.
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes for each stage of the LLM journey, from data preparation to training and deployment. You can deploy and manage it using either Slurm or Kubernetes orchestration platforms — read more here.
In other key AWS news from the past month…
New EventBridge console dashboard
The new console dashboard surfaces account level metrics, providing deeper insight into your event-driven applications and allowing you to quickly identify and resolve issues as they arise.
You can use the dashboard to answer basic questions such as “How many Buses and Pipes have I configured in my account?”, “What was my PutEvent traffic pattern for the last 3 hours?” or “What is the concurrency of my Pipe?”. It is available by default in the EventBridge console in all AWS Regions.
Amazon OpenSearch Service announces Natural Language Query Generation for log analysis
This feature lets you ask log exploration questions in plain English, which are then automatically translated to the relevant Piped Processing Language (PPL) queries and executed to fetch the requested data.
This opens up log analysis to a wider set of team members who don’t need to be proficient in PPL — they can simply explore their log data by asking questions like “show me the count of 5xx errors for each of the pages on my website” or “show me the throughput by hosts”.
New controls make it easier to search, filter, and aggregate Lambda function logs
Amazon ECS now enforces software version consistency for containerized applications
Amazon ECS now automatically enforces software version consistency for services created or updated after June 25 2024, running on AWS Fargate platform version 1.4.0 or higher and/or version v1.70.0 or higher of the Amazon ECS Agent in all commercial and the AWS GovCloud (US) Regions.
This helps prevent inconsistencies and enhance the reliability and predictability of deployments.
The best AWS engineering blogs from July 2024
How to Work With IPv6 in AWS and Not Die in the Process
Starting February 1, 2024, AWS began charging $0.005 per IP per hour for all public IPv4 addresses, which were previously free when used with actively running services. This change has been praised by some as a step towards incentivizing good internet hygiene.
While it may not yet be the end of the IPv4 era, many companies are migrating to IPv6 — check out this great article on how to do it as painlessly as possible.
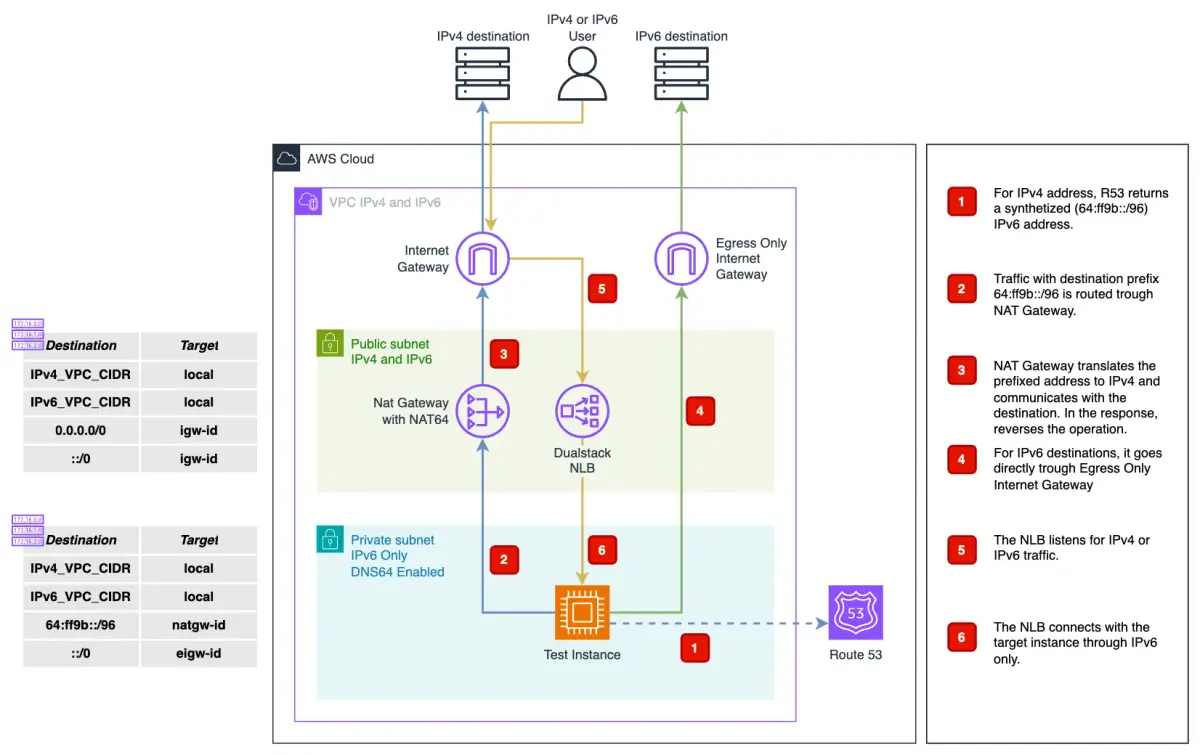
Sample architecture implementing a VPC with a public dual-stack subnet, and a private IPv6 only subnet (image source: AWS)
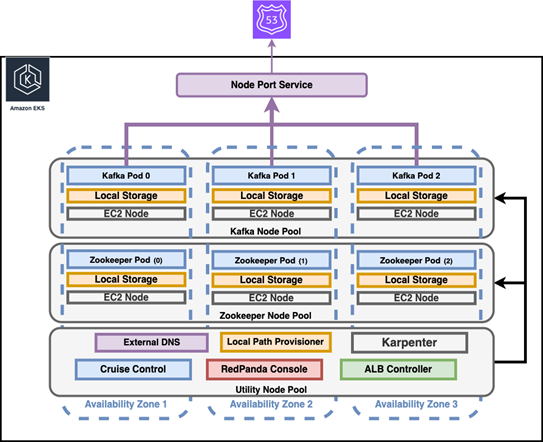
Harnessing Karpenter: Transitioning Kafka to Amazon EKS with AWS solutions
Here at nOps, we’re big fans of Karpenter.
Find out how it can help in complex data environments in this case study — featuring AppsFlyer’s journey to Karpenter and how it unlocked new efficiencies for production Kafka clusters.
AWS Cloud Cost Allocation: The Complete Guide

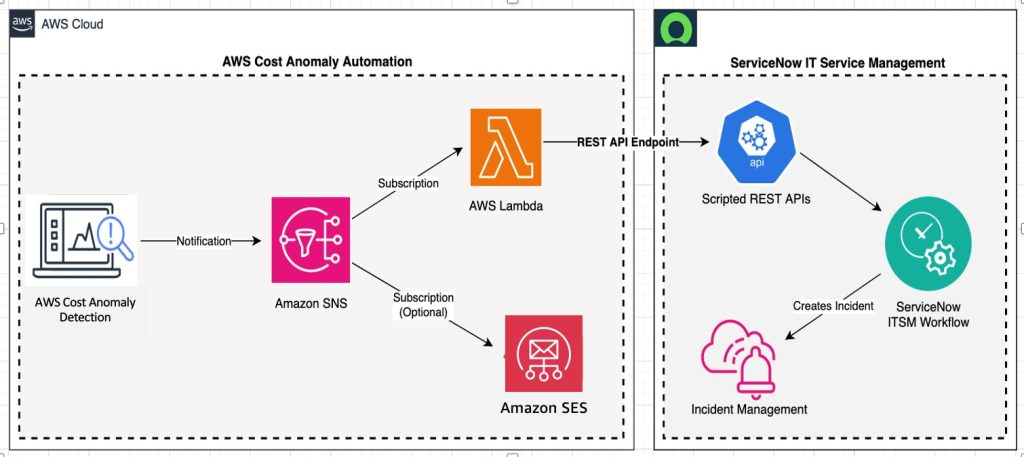
Integrate AWS Cost Anomaly Detection Notifications with IT Service Management Workflow
Enable CloudWatch memory metrics for Windows EC2 instances with Systems Manager
This blog post demonstrates how to reduce the administrative burden of enabling Amazon CloudWatch memory metric monitoring on Windows Server EC2 instances using AWS Systems Manager automation.
Once enabled, you can use it with downstream services like AWS Compute Optimizer for more accurate cost savings recommendations
About nOps
If you’re looking to save on your AWS costs, nOps makes it easy and painless for engineers to take action on cloud cost optimization.
The nOps all-in-one cloud platform features include:
- Business Contexts: Understand and allocate 100% of your AWS bill down to the container level
- Compute Copilot: Intelligent provisioner that helps you save with Spot discounts to reduce On-Demand costs by up to 90%
- Commitment management: Automatic life-cycle management of your EC2/RDS/EKS commitments with risk-free guarantee
- Storage migration: One-Click EBS volume migration
- Rightsizing: Rightsize EC2 instances and Auto Scaling Groups
- Resource Scheduling: Automatically schedule and pause idle resources
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $1.5+ billion in cloud spend for our customers.
Join our customers using nOps to understand your cloud costs and leverage automation with complete confidence by booking a demo today!








