Skip to content
Skip to content
.png?width=1920&height=1080&name=Landscape%20(4).png)


Why we use Databricks at nOps
If you’ve been working in tech, you’ve likely observed a shift over the last ten years. It used to be that we did a lot of the data processing and heavy lifting in the API and backend layer. But with streaming, near real-time analytics, AI and other advanced use cases, every problem is becoming a data problem.
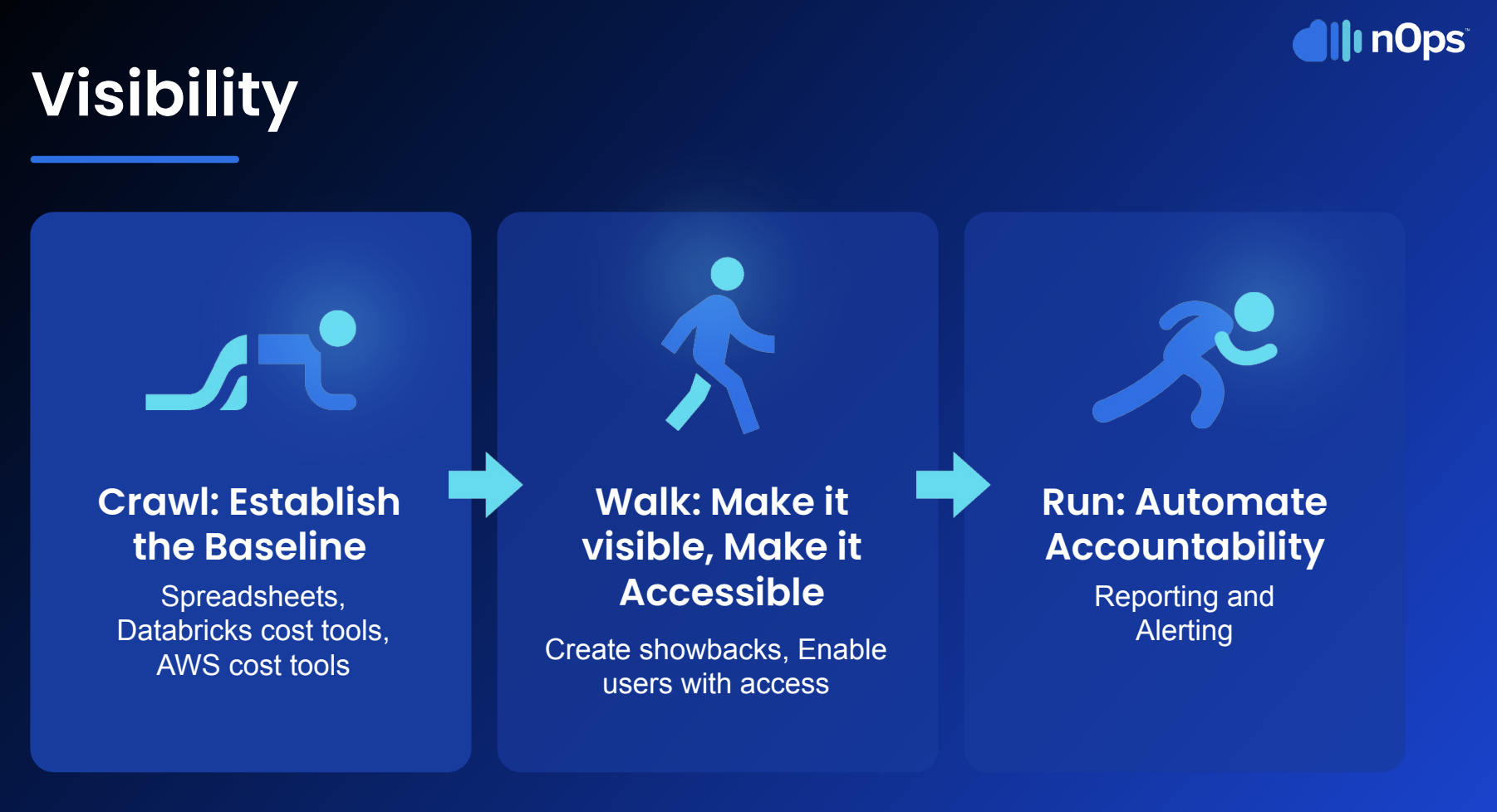
When we were building out the nOps platform around 3 years ago, we were looking for a scalable data solution that would allow our engineers to focus on building and innovating rather than on operating the tools we needed. We started to experiment with Databricks, and the benefits in terms of scalability, performance and reliability were just the beginning. What began as a set of tools became a platform entirely built on Databricks.
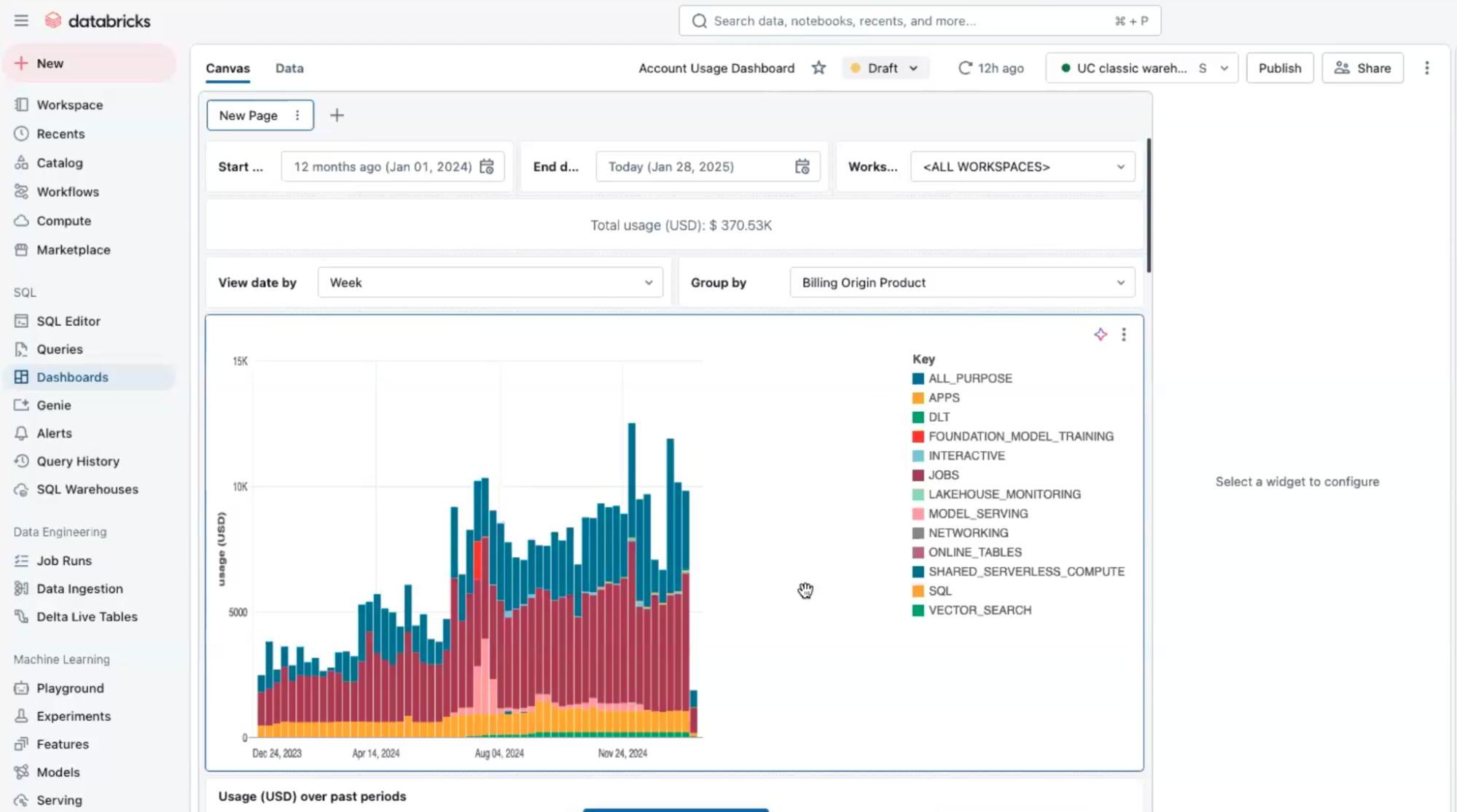
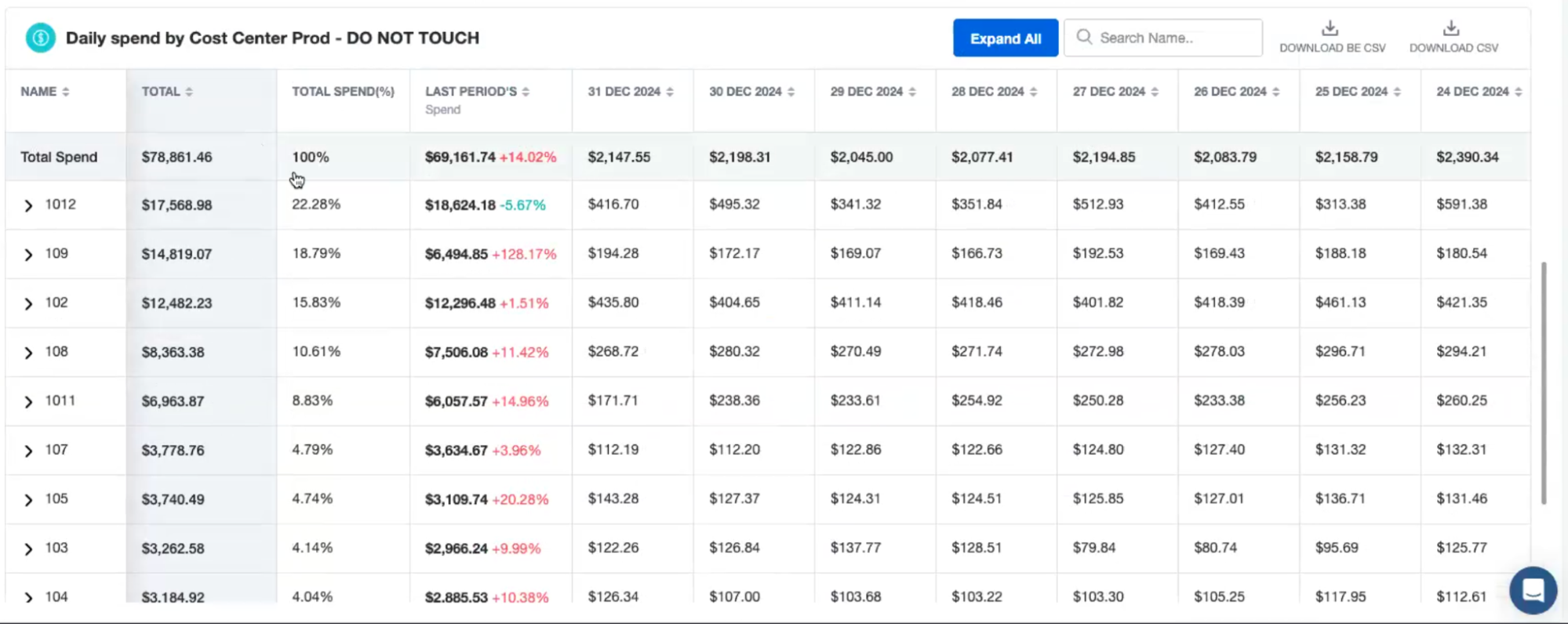
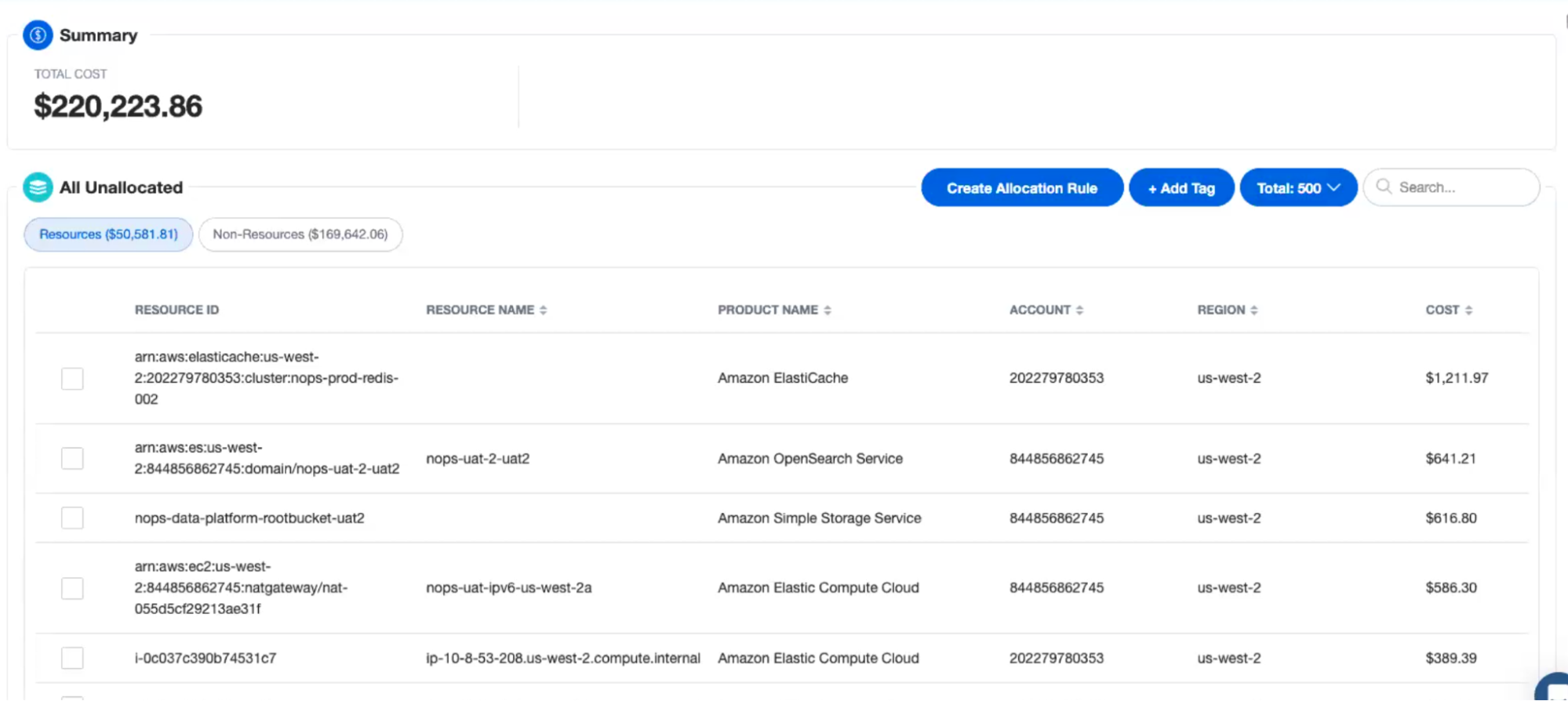
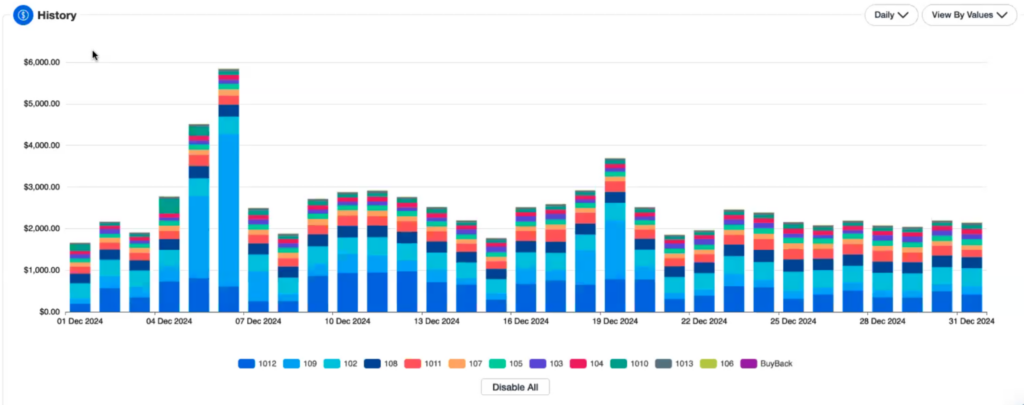
Today, we ingest all our data using Databricks workload orchestration, leveraging workload flows and task features. We run all our Spark and data transformation workloads on Databricks, preparing data to drive recommendations and real-time automation that give our customers insight into their public cloud spend and the ability to take action to cut costs. For us, Databricks has been essential to moving fast and delivering on innovation.
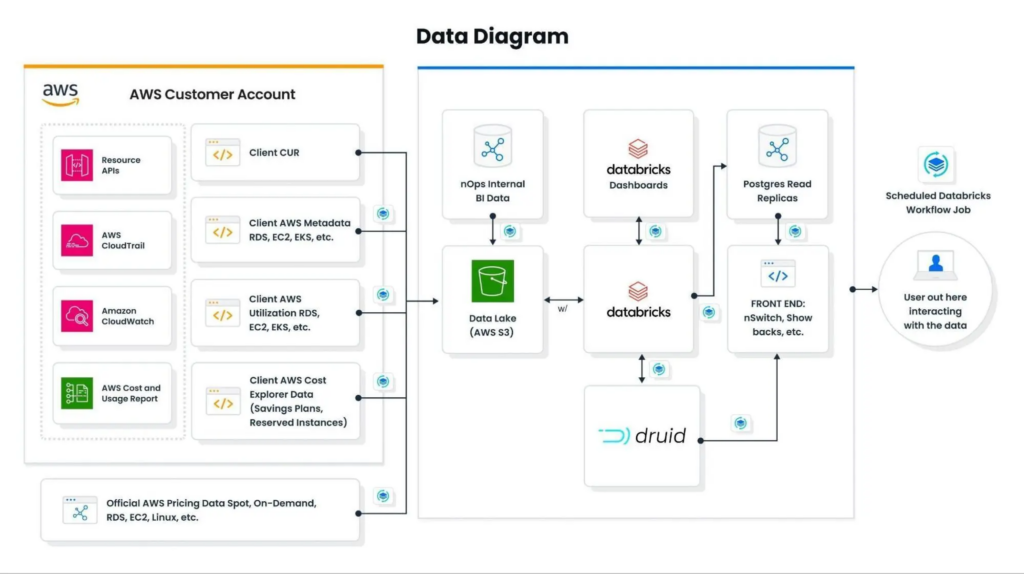
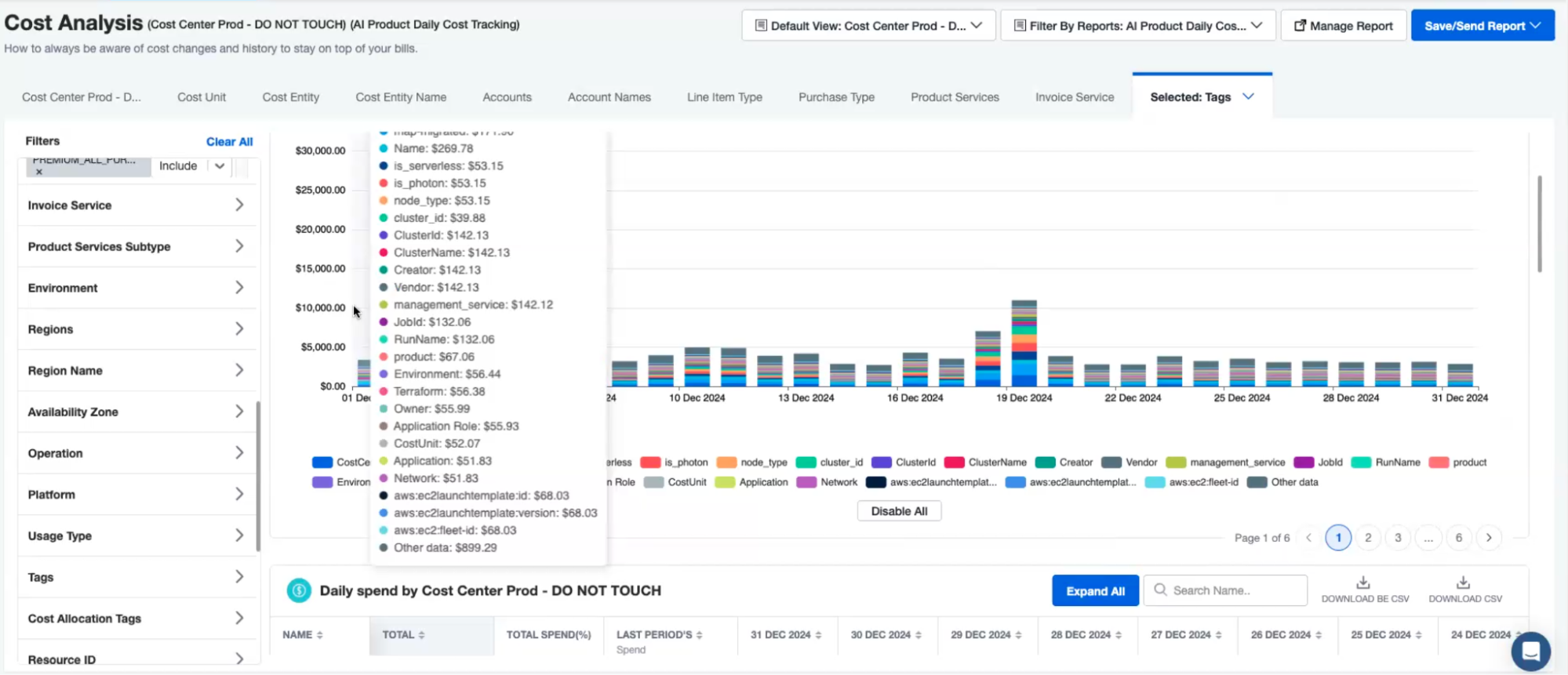
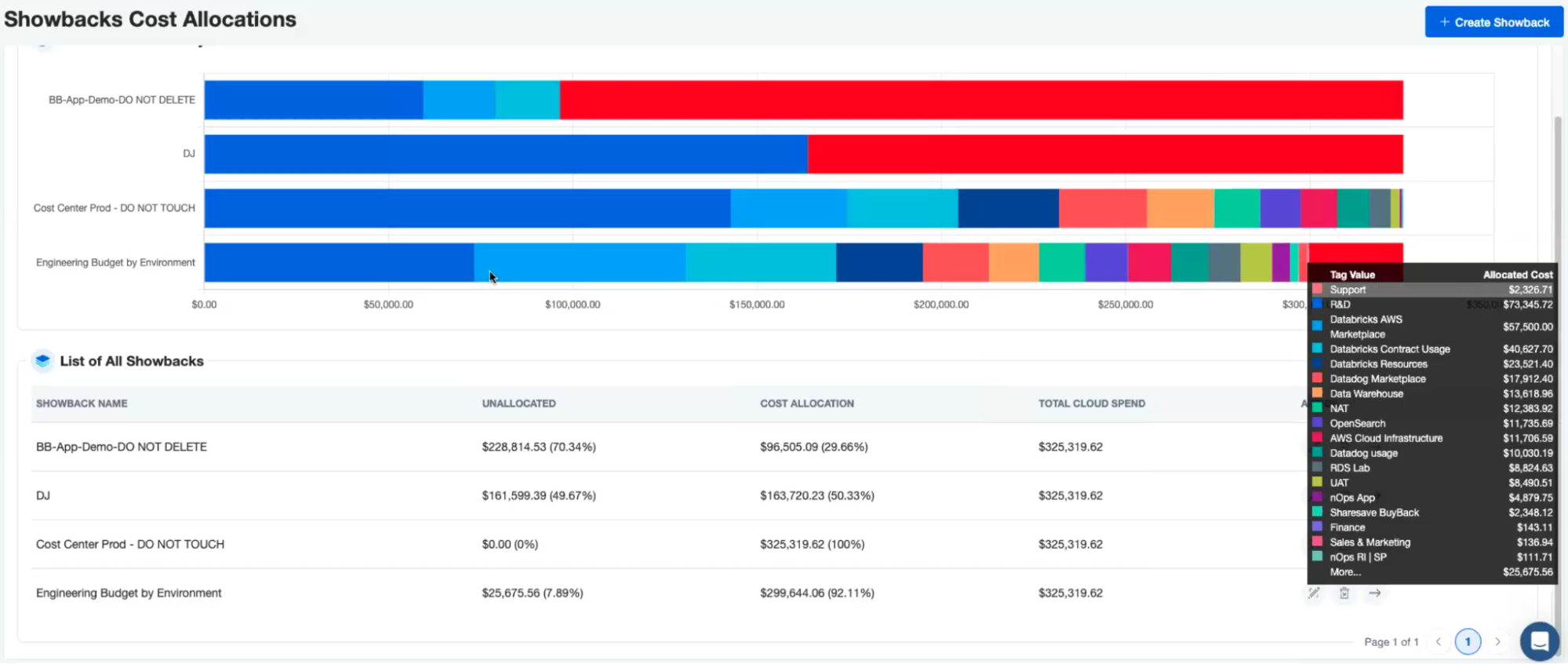
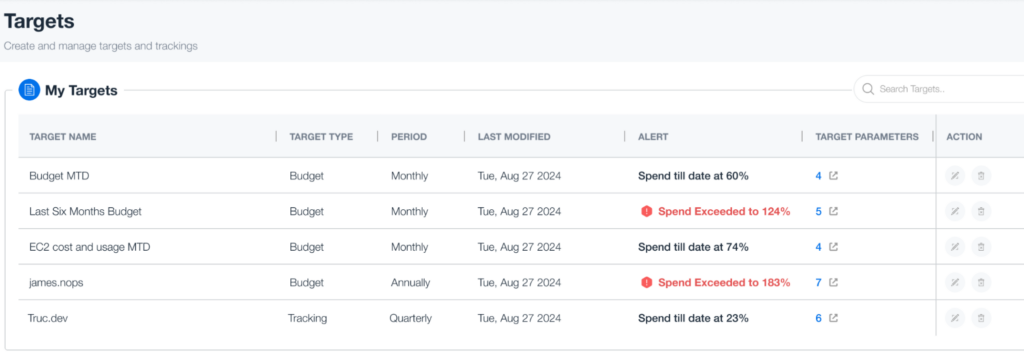
By analyzing an organization’s AWS usage patterns, nOps can provide automation to make changes to optimize costs without sacrificing performance. This can include recommendations and automated provisioning on areas such as optimal instance reservations, unused resources, underutilized instances, and Spot.