 Skip to content
Skip to content
.png?width=1920&height=1080&name=Landscape%20(4).png)


AWS Auto Scaling automatically adds or removes resource capacity for your applications in response to changing demand. This helps you more easily maintain predictable performance and align cost to usage. You can use the AWS Auto Scaling user interface to build scaling plans for various AWS resources such as Amazon EC2 instances, Spot Fleets, Amazon ECS, DynamoDB, and Amazon Aurora Replicas.
This article will cover AWS Auto Scaling, its benefits, how it works across various AWS services, best practices, and commonly asked questions.
EC2 Auto Scaling
Manual scaling would be inefficient and time consuming. Luckily, EC2 Auto Scaling lets you automatically add or remove EC2 instances as demand changes, using scaling policies that you define. Based on your policies, AWS will automatically launch new instances and terminate old unhealthy ones as needed.
For example, dynamic policies can be triggered by performance-based metrics, CloudWatch alarms, events from Amazon services such as SQS or S3, or a predefined schedule.
Here are the basic steps for drafting a launch template and configuring EC2 Auto Scaling:
- Step #1: Draft a Launch Template. Launch Templates define the settings for launching instances, like the ID of the Amazon Machine Image (AMI), the instance type, a key pair, security groups, and other parameters. (Launch Template used to be called Launch Configuration).
- Step #2: Set up AWS Auto Scaling Groups. Once the Launch Template defines what to scale, the ASG determines where to launch the EC2 instances. You can specify the initial, minimum, maximum, and preferred number of running instances.
- Step #3: Implement Elastic Load Balancer. When an EC2 instance fails, the load balancer can reroute traffic to the next available healthy EC2 instance.
- Step #4: Set Autoscaling Policies. For example, a policy might be to scale out when CPU utilization exceeds 80% for a period and scale in when it drops below 30%. Advanced configurations might consist of scaling policies tracking multiple targets and/or step scaling policies for coverage of various scenarios.
You can learn more in our complete guide to EC2 Auto Scaling.
AWS Application Auto Scaling
Application Auto Scaling helps scale resources for individual AWS services beyond Amazon EC2. With Application Auto Scaling, you can configure automatic scaling for the following:
- AppStream 2.0 fleets
- Aurora replicas
- Amazon Comprehend document classification and entity recognizer endpoints
- DynamoDB tables and global secondary indexes
- Amazon ECS services
- ElastiCache for Redis clusters (replication groups)
- Amazon EMR clusters
- Amazon Keyspaces (for Apache Cassandra) tables
- Lambda function provisioned concurrency
- Amazon Managed Streaming for Apache Kafka (MSK) broker storage
- Amazon Neptune clusters
- SageMaker endpoint variants
- SageMaker inference components
- SageMaker Serverless provisioned concurrency
- Spot Fleet requests (Spot instances and On Demand instances)
Let’s discuss a few concepts that are key to AWS Application Auto Scaling.
Scalable target
A scalable target specifies the resource you want to auto scale, uniquely identified by service namespace, resource ID, and scalable dimension. For example, an Amazon ECS service supports auto scaling of its task count, a DynamoDB table supports auto scaling of the read and write capacity of the table and its global secondary indexes, and an Aurora cluster supports scaling of its replica count.
Each scalable target has defined minimum and maximum capacities.
Scale in / Scale Out
When Application Auto Scaling automatically decreases capacity for a scalable target, the scalable target scales in. When scaling policies are set, they cannot scale in the scalable target lower than its minimum capacity.
And vice versa, when Application Auto Scaling automatically increases capacity for a scalable target, the scalable target scales out, not higher than its maximum capacity.
Scaling policy
A scaling policy instructs Application Auto Scaling to track a specific CloudWatch metric to determine whether to scale out or in. We’ll discuss this concept in more detail later.
Scheduled action
Scheduled actions in AWS automatically adjust resource levels at specified times by altering the minimum and maximum capacities of a scalable target. This enables applications to scale up or down based on a set schedule, such as reducing capacity on weekends and increasing it on Mondays.
EKS Autoscaling
In Kubernetes, including AWS Elastic Kubernetes Service (EKS), autoscaling can be configured at both the pod and node levels to efficiently manage AWS resources and application demands:
Pod-level scaling
Horizontal scaling involves adding multiple servers to an existing pool of machines to handle increased load, rather than upgrading the capabilities of an existing machine. In EKS, this is typically done with Horizontal Pod Autoscaler (HPA), which dynamically adjusts the number of pod replicas in a deployment based on observed metrics like CPU or custom metrics.
On the other hand, vertical scaling involves adding additional capabilities (such as processing power, memory or storage) to a single machine, to manage higher loads without adding multiple machines to the system. This is done with Vertical Pod Autoscaler (VPA).
Node-level scaling
While HPA and VPA are integral for optimizing resource usage at the pod level, managing the underlying infrastructure’s scalability is crucial for comprehensive resource optimization. This is where Cluster Autoscaler and Karpenter, the two most popular EKS node scaling solutions, are integral.
Cluster Autoscaler (CA) automatically scales your Kubernetes clusters based on the metrics you define. Cluster Autoscaler monitors the resource utilization of nodes in your EKS/Kubernetes Cluster, and scales up or scales down the number of nodes in a node group accordingly. Cluster Autoscaler makes scaling decisions intelligently, evaluating both node usage and factors like pod priority and PodDisruptionBudgets to make scaling decisions, minimizing disruptions.
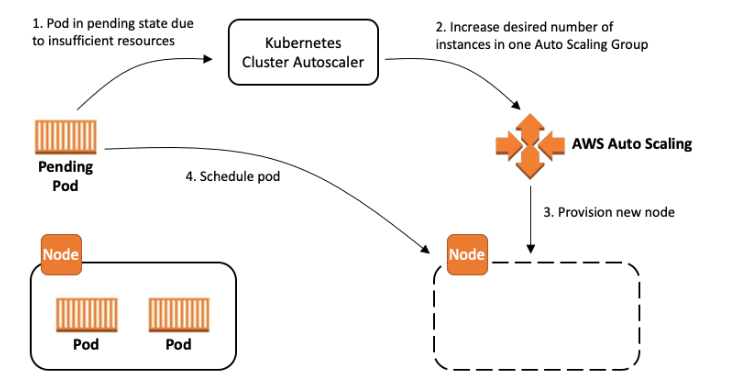
The Ultimate Guide to Karpenter

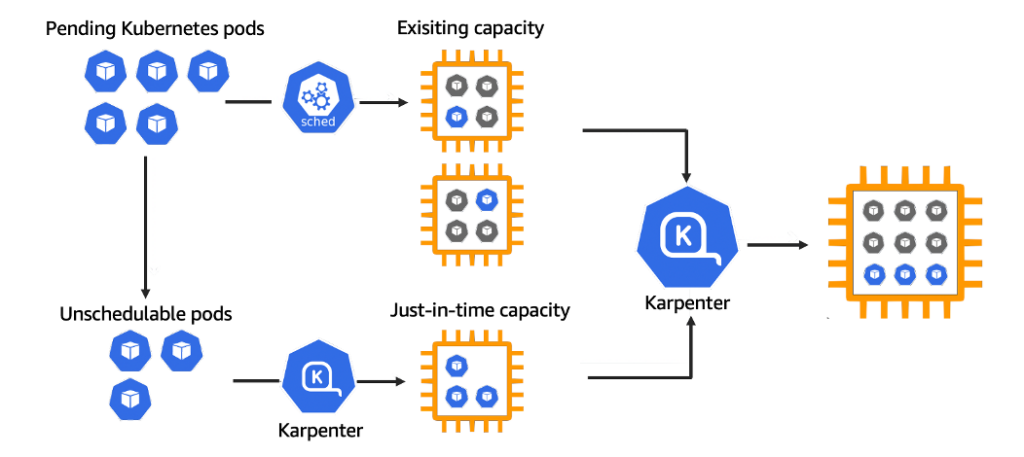
Scaling policy vs Scaling plan
A scaling policy is a rule-based trigger for adjusting resource capacity within a specific service (e.g., EC2 Auto Scaling). It can be based on metrics (like CPU usage) or schedules, offering granular control over scaling actions. There are three main types:
- Target Tracking Scaling: You set a target metric, and capacity is maintained at that level.
- Step Scaling: Capacity is adjusted by predefined steps, triggered based on the magnitude of the deviation from a target metric, as monitored by alarms.
- Scheduled Scaling: Predefined adjustments based on the date and time, in response to expected changes in demand.
On the other hand, a scaling plan is a broader strategy managed by AWS Auto Scaling that optimizes resource scaling across multiple services (e.g., EC2, ECS, DynamoDB). It uses predictive scaling and dynamic scaling methods to adjust resources based on application demands and forecasted usage.
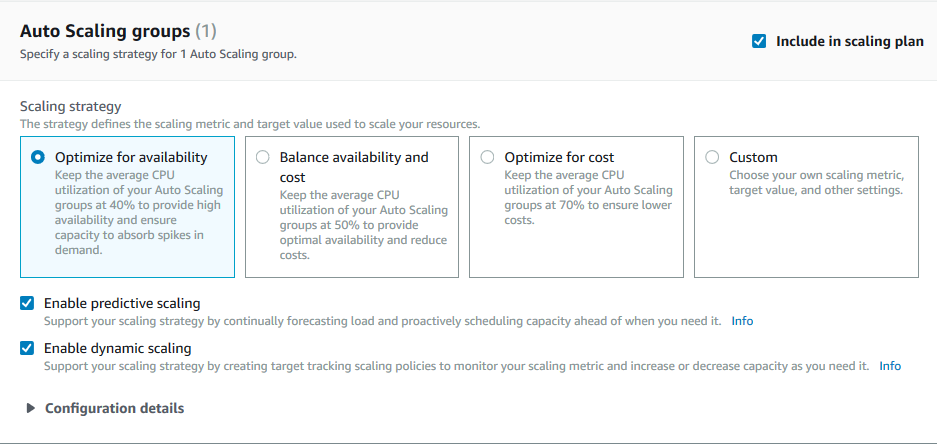
What is an Auto Scaling Group?
An AWS Auto Scaling Group (ASG) treats multiple EC2 instances as a single unit, for easier scaling and management. This grouping allows you to define parameters such as the minimum number, maximum number, and desired number of instances, ensuring that your application always has the appropriate resources to handle varying loads efficiently.
With AWS Auto Scaling Groups, you can leverage Amazon EC2 Auto Scaling functionalities, including health checks and scaling policies. These features automatically adjust the number of EC2 instances in your group in response to real-time demand, performance metrics, or predefined schedules, helping maintain steady performance and availability.
Load balancing vs Auto Scaling
Load balancing distributes incoming traffic across multiple instances to ensure optimal performance and reliability, while auto scaling dynamically adjusts the number of instances based on demand to maintain application availability and efficiency.
Auto scaling and load balancers work together to help resources respond to demand. They help ensure that your applications can efficiently handle varying loads, reducing the risk of downtime during traffic spikes or instance failures.
How can nOps help with AWS Auto Scaling?
nOps Compute Copilot automatically optimizes your AWS auto scaling for better performance at lower costs. It integrates with your Auto Scaling Groups, Batch, ECS, Cluster Autoscaler or Karpenter for AI-driven management of ASG instances for the best price in real time.
It continually analyzes market pricing and your existing commitments to ensure you are always on an optimal blend of Spot, Reserved, and On-Demand. And with 1-hour advance ML prediction of Spot instance interruptions, you can run production and mission-critical workloads on Spot with complete confidence.
Here are the key benefits:
- Hands free. Copilot automatically selects the optimal instance types for your workloads, freeing up your time and attention for other purposes.
- Cost savings. Copilot ensures you are always on the most cost-effective and stable Spot options, whether you’re currently using Spot or On-Demand.
- Enterprise-grade SLAs for safety and performance. With ML algorithms, Copilot predicts Spot termination 60 minutes in advance. By selecting diverse Spot instances with negligible risk of near-term interruption, you enjoy the highest standards of reliability.
- No proprietary lock-in. Unlike other products, Copilot works directly with AWS ASG. It doesn’t alter your ASG settings or Templates, so you can effortlessly disable it any time.
- Effortless onboarding. It takes just five minutes to onboard, and requires deploying just one self-updating Lambda for ease and simplicity.
- No upfront cost. You pay only a percentage of your realized savings, making adoption risk-free.
With Compute Copilot, you benefit from Spot savings with the same reliability as on-demand.
nOps was recently ranked #1 in G2’s cloud cost management category. Join our customers using Compute Copilot to save hands-free by booking a demo today!








