 Skip to content
Skip to content


- Blog
- AWS Pricing and Services
- Amazon Bedrock Pricing Explained 2026
Amazon Bedrock Pricing Explained 2026
Generative AI usage is ramping quickly—Gartner estimates global GenAI spending will reach $644B in 2025, up 76.4% year over year. That growth is great for innovation, but it also means teams need a clear handle on what they’re paying for and why.
Amazon Bedrock makes it easy to use multiple foundation models through one managed API, yet the pricing has several moving parts. Costs start with inference (tokens for text models, images for image models, tokens for embeddings), then change based on which pricing mode you use—on-demand, batch, or provisioned throughput. On top of that, optional capabilities like customization, evaluations, knowledge bases/embeddings, guardrails, and data transfer can materially shift your bill.
Here at nOps, we manage and optimize $2 billion in cloud and AI spend — we wrote this guide to break down Bedrock’s pricing pieces, compare model costs, and share practical ways we’ve learned to forecast and lower spend.
What is Amazon Bedrock?
Amazon Bedrock is a fully managed service for AI and Machine learning that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Bedrock simplifies AI deployment by providing scalable, pay-as-you-go access to computing resources and model customization options, allowing users to tailor AI functions to specific business needs and operational contexts such as text generation, image processing, and custom model training. Besides building and running models, Bedrock includes features for evaluating model performance, knowledge bases, responsible AI guardrails, agentic capabilities and prompt management.
In this guide, we’ll take you through the various factors that impact Bedrock pricing, compare the best and latest models (think Meta Llama versus Anthropic cage match), and offer strategies for getting more out of every dollar you spend on Bedrock.
How does Amazon Bedrock pricing work?
Bedrock pricing can be fairly complex, but there are four key factors driving your costs: compute, model, storage, and data transfer.
Costs are based on the compute power required to run AI models, the storage needed for datasets and custom models, and the volume of data transfer during operations. Additionally, different foundation models have their own pricing structures, so selecting the appropriate model is essential for optimizing cost savings.

What is the Amazon Bedrock pricing model?
On-Demand Bedrock Model Pricing:
This model is most flexible, charging users only for the resources they use without any long-term commitments. Charges are based on the number of input tokens processed and output tokens generated for text models, each image for image models, and input tokens for embeddings models. (A token, comprising of a few characters, refers to the basic unit of text that a model learns to understand the user input and prompt).
On-Demand pricing also supports cross-region model inference, allowing users to handle traffic spikes by utilizing AWS’s global infrastructure without additional cross-region charges. The price is calculated based on the region you made the request in, i.e. the source region.
This model is ideal for businesses with variable AI workload demands that cannot predict usage volume in advance.
Provisioned Throughput
Designed for large consistent inference workloads requiring guaranteed throughput, this model allows users to purchase capacity ahead of time, measured in model units. Charges are incurred hourly, with options for 1-month or 6-month commitments. This model suits use cases with predictable, high-volume workloads and is the only option for accessing custom models.
Currently, Amazon Titan, Anthropic, Cohere, Meta Llama and Stability AI offer provisioned throughput pricing, ranging from $21.18 per hour per model unit for a 1-month commitment (Meta Llama) to $49.86 per hour per model unit for a 1-month commitment (Stability.ai).
Model Customization & Impact on AWS Bedrock Models Pricing
Batch Mode:
Model Evaluation:

For automatic evaluations, users only pay for the model inference used, and algorithmic scores are provided at no additional cost. In contrast, human-based evaluations involve charges for model inference plus a fee of $0.21 per completed human task, where a task is defined as a human worker evaluating a single prompt and its responses.
These charges apply uniformly across all AWS Regions and are billed under the Amazon SageMaker line item, irrespective of the number of models or evaluation metrics used. There’s no separate fee for the workforce, as users supply their own evaluators. For more tailored needs, AWS provides customized pricing in private engagements through their expert evaluations team.
Custom Model Import
Custom Model Import in Amazon Bedrock lets you bring your existing model customizations into Bedrock’s fully managed environment, just like its hosted foundation models. You can import custom weights for supported architectures at no cost and serve your custom model using On-Demand mode without needing any control plane actions.
You are only charged for model inference based on the number of model copies needed to handle your inference volume and the duration each model copy is active, billed in 5-minute increments. A model copy is a single instance of your imported model ready to serve inference requests. The price per model copy per minute varies depending on factors such as the architecture, context length, AWS Region, compute unit version (hardware generation), and is tiered by model copy size.
Amazon Bedrock Guardrails Pricing
How to reduce AWS Bedrock Costs: Best Practices
Optimize Prompts to Reduce AWS Bedrock Token Cost

Some tips include:
- Craft concise and clear prompts by eliminating unnecessary words or phrases.
- Use precise language to reduce ambiguity, which can also improve model responses.
- Set maximum token limits for the model’s output to control the length of responses.
Utilize Batch Mode for Large-Scale Inference
Batch Mode processing is priced at 50% less than On-Demand rates for selected models, making it ideal for large volumes of data that don’t require immediate responses.
- Aggregate inference tasks and submit them as batch jobs.
- Schedule batch processing during off-peak hours to maximize resource availability.
- Store and manage batch responses in Amazon S3 for easy access and analysis.
Implement Efficient Data Preprocessing
Reducing the amount of data processed not only enhances model performance but also lowers operational costs. This is crucial when building an end-to-end GenAI pipeline.
- Cleanse data to remove irrelevant or duplicate information before processing.
- Use data compression techniques where applicable to minimize data size.
- Normalize data formats to ensure consistency and reduce processing overhead.
Leverage Provisioned Throughput for Predictable Workloads
For applications with consistent usage patterns, Provisioned Throughput is ideal.
- Analyze your application’s usage metrics to determine predictability.
- Choose a 1-month or 6-month commitment based on your forecasted needs.
- Monitor throughput utilization to adjust provisioned capacity as necessary.
Implement Best Practices for Storage & Data Transfer
Optimizing your data storage and data transfer strategies can lead to significant cost reductions in your AWS Bedrock usage.
- Use appropriate storage classes like Amazon S3 Standard-Infrequent Access or S3 Glacier for infrequently accessed data & set up S3 Lifecycle policies to automatically transfer data to lower-cost storage tiers.
- Keep transfers within the same region whenever possible and compress data before transfer.
- Use VPC Endpoints or PrivateLink when transferring data between services within AWS.
Monitor Resource Usage and Set Up Cost Alerts
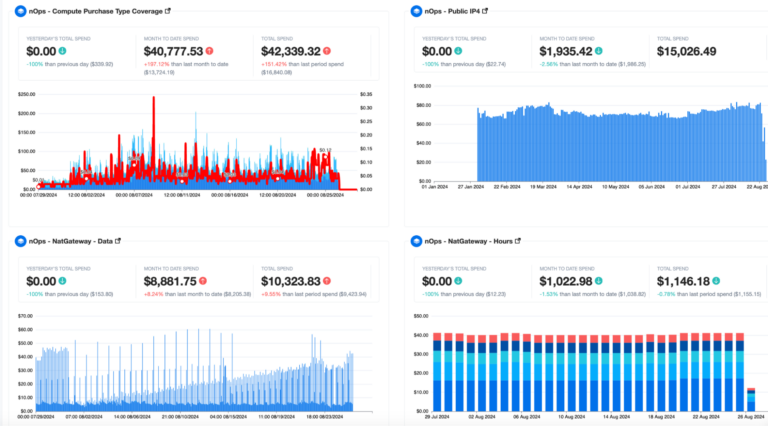
nOps was recently ranked #1 with five stars in G2’s cloud cost management category, and we optimize $1.5+ billion in cloud spend for our customers.
To find out to get complete cost visibility, allocate 100% of AWS costs, and start eliminating cloud waste, book a demo with one of our FinOps experts.
Select the Right Foundation Model and understand Bedrock LLM Pricing
Different foundation models vary in capabilities and costs; choosing the most appropriate model is key for cost optimization.
- Evaluate the specific requirements of your application (e.g., complexity, response time).
- Test multiple models to compare performance against cost.
- Opt for smaller or less complex models if they meet your application’s needs adequately
Amazon Bedrock Models Pricing Compared
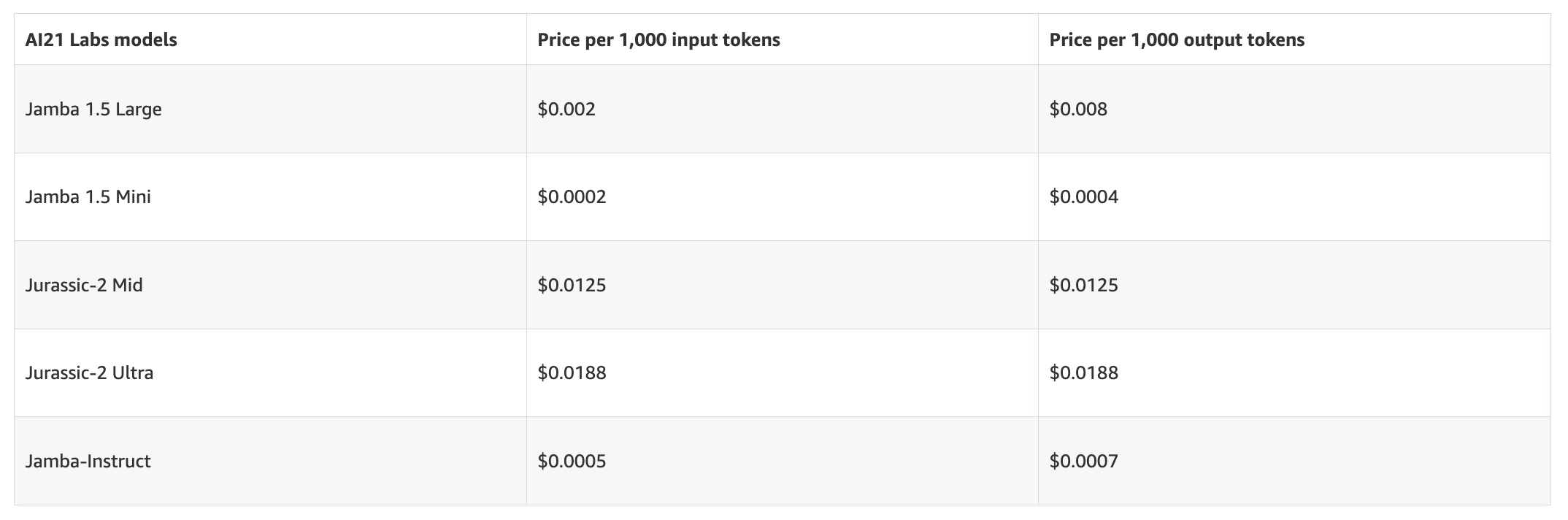
AI21 Labs
AI21 Labs is an Israeli company specializing in Natural Language Processing (NLP). It’s known for its text generation models tailored for applications requiring complex content generation, such as automated writing assistants and content summarization tools.
AI21 Labs offers On-Demand pricing for their models, charging per 1,000 input and output tokens.
Amazon Titan
Amazon Titan provides high-performance AI models that serve a broad spectrum of complex machine learning applications, including image recognition, natural language processing, and predictive analytics. Designed for high accuracy and processing speed, Titan models are suitable for enterprises that demand dependable and scalable AI solutions for essential business functions.
Amazon Titan offers both On-Demand and Provisioned Throughput pricing:
Text Models:
- Amazon Titan Text Express: $0.0008 per 1,000 input tokens and $0.0016 per 1,000 output tokens.
- Amazon Titan Text Embeddings V2: $0.00011 per 1,000 input tokens.
Multi-Modal Models:
- Image Generation Models: Prices vary based on image size and quality.
Amazon Titan also provides options for model customization and Provisioned Throughput for applications requiring guaranteed performance; you can consult the complete list here.
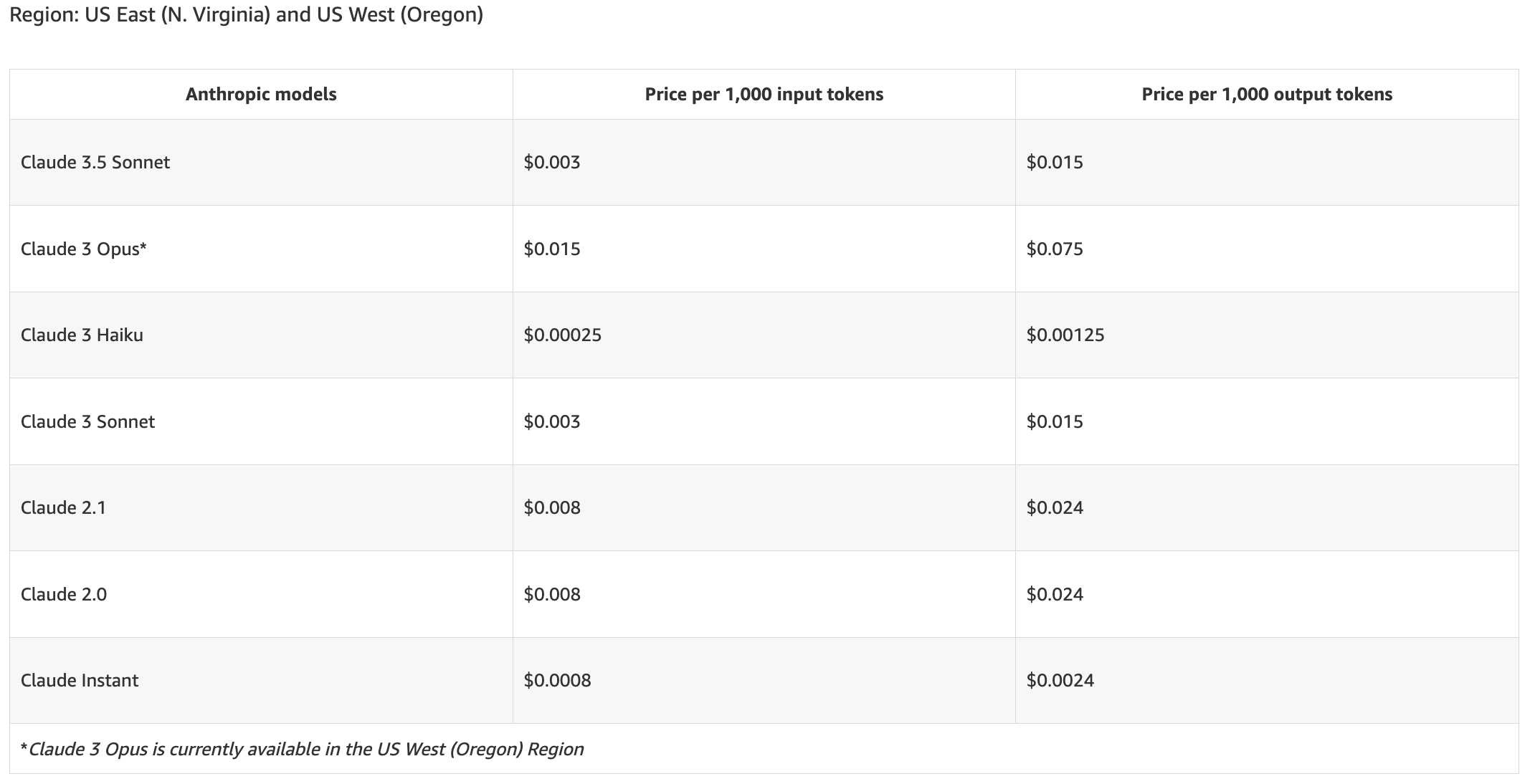
Anthropic
Anthropic is an AI startup that specializes in developing AI models that prioritize safety and interpretability, focusing on ethical AI development. The company designs its models to minimize unpredictable behaviors and enhance the clarity of decision-making processes. Anthropic has developed the Claude family of large language models (LLMs) as a competitor to OpenAI’s ChatGPT and Google’s Gemini.
Anthropic offers On-Demand pricing across various AWS regions. For example:
Cohere
Cohere, a Canadian multinational company specializes in LLMs designed for their ability to comprehend and generate human-like text, supporting diverse applications from chatbots to intricate document analysis.
Cohere provides On-Demand pricing tailored to different model capabilities:
- Command Model: $0.0015 per 1,000 input tokens and $0.0020 per 1,000 output tokens.
- Command-Light Model: $0.0003 per 1,000 input tokens and $0.0006 per 1,000 output tokens.
- Embedding Models:
- Embed – English: $0.0001 per 1,000 input tokens.
- Embed – Multilingual: $0.0001 per 1,000 input tokens.
For businesses requiring custom solutions, Cohere offers model customization and Provisioned Throughput pricing options.

Meta Llama
Meta Llama specializes in AI models that are customized for integration with social media platforms and digital marketing tools. These models excel in generating engaging content, analyzing user sentiment, and automating interactions on digital platforms.
Meta Llama offers On-Demand pricing based on model size:
- Llama 3.2 Instruct (1B): $0.0001 per 1,000 input and output tokens.
- Llama 3.2 Instruct (11B): $0.00035 per 1,000 input and output tokens.
- Llama 3.2 Instruct (90B): $0.002 per 1,000 input and output tokens.
Provisioned Throughput pricing is available for businesses needing guaranteed performance and scalability.
Mistral AI
Mistral AI is a French company specializing in AI products. The company focuses on producing open source large language models, emphasizing the foundational importance of free and open-source software, and positioning itself as an alternative to proprietary models.
It offers On-Demand pricing:

Stability AI
Stability AI is an artificial intelligence company, best known for its text-to-image model Stable Diffusion. It’s notable for its development of creative AI models used in the arts and design fields for the creation of unique visual content, music, and interactive media experiences.
Stability AI charges on a per-image basis:

Optimize Bedrock with nOps
Understanding Bedrock pricing is the first step, but it won’t tell you which models, teams, features, or customers are driving that spend — or where you’re wasting money.
That’s where nOps comes in.
nOps gives you deep, real-time visibility into every token, API call, and workload across all your large language model providers. Instead of seeing “$27,400 in LLM spend,” you can break it down by model, by team, by feature, or even by customer to understand true AI COGS and business impact.
With nOps, you can:
Track costs AI, cloud, SaaS, and K8s spend in one place, with real-time token and API analytics
Allocate costs automatically to teams, products, or customers — no tagging needed
Catch anomalies early with alerts on token spikes, agent loops, or runaway workloads
Get model-switch recommendations to cut costs while maintaining output quality
Benchmark models across cost, speed, and accuracy using industry-standard metrics
Forecast spend with confidence so finance isn’t blindsided by next month’s bill
Use an AI FinOps agent to answer questions instantly in natural language
If you want to connect AI usage to real business value, nOps gives you the visibility and intelligence to do it.
nOps manages $2 billion in AWS spend and was recently rated #1 in G2’s Cloud Cost Management category — book a demo to try it out wiht your own AWS account for free.
Frequently Asked Questions
How to estimate Amazon Bedrock costs for public sector applications?
Estimate Bedrock costs by projecting monthly input/output tokens per use case, selecting models, and checking on-demand vs provisioned throughput rates. Add charges for customization/fine-tuning, Knowledge Bases (embeddings/storage), Agents, guardrails, logging/monitoring, and data transfer. Pilot to validate assumptions, then reforecast quarterly, especially for GovCloud regions. You can track it all easily in nOps.
Last Updated: February 17, 2026, AWS Pricing and Services
Tags
Last Updated: February 17, 2026, AWS Pricing and Services
